评测一: 医学对话临床发现阴阳性判别任务
Task1: Classifying Positive and Negative Clinical Findings in Medical Dialog Task
任务简介
临床发现(Clinical Finding)是临床医学下,病人状态描述的概念集合,每一个临床发现的概念都具有明确的涵义(比如腹泻,呕吐,高温,物理降温,降温药物治疗),医学为了保证其严谨性对每一个概念都进行了明确的定义和说明。
医学临床报告是病人状态的汇总性的描述,为了尽可能全面和精准的对病人的状态进行客观描述,需要利用严谨的临床发现的概念对病人状态进行表达,其中最基本的状态就是阴性和阳性,也就是病人是否存在或者发生某一种明确的临床发现(Clinical Finding)。
目前互联网医疗患者会对自己的症状进行一些口语化的描述,一般称之为主诉,同时医生也为针对性的进行一些问诊,来进行一些主诉的细化和补充。针对互联网医疗对话场景,阿里巴巴夸克团队计划在CHIP会议上开展一系列学术评测任务,本次评测是第一期,主要是对互联网在线问诊记录中的临床发现的部分进行阴阳性的分类判别。
任务详情
本次标注数据全部来源于春雨医生的互联网在线问诊的公开数据。阴阳性的定义一般认为是患者主诉病情描述和医生诊断判别中的阴性和阳性。SOAP(Subjective,Objective,Assessment,Plan) 评估记录法是目前国际上最常用以问题为导向的医学记录方法,阴阳性需要处理主要是S和A中相关的实体的判别。数据预处理是先对齐进行SOAP分类,然后对S和A的部分进行NER识别,然后在此基础上进行阴阳性的标注。 注:并不是对话中所有的临床发现的NER的部分都需要进行识别和标注,只需要对表述病人主客观存在的临床发现,以及对应的诊断结果进行判别。
阴阳性标注标准
一、标注属性
阴性、阳性、其他、不标注
二、标注标准
共分为四类,本期评测涉及到对话类的,医患的交互中的症状/疾病,
需要考虑上下文联系、逻辑关系,来对症状的阴阳性和“其他”(一般用户没有回答,或者回答不明确,不知道)来做判断。
(1)阳性(pos):已有症状疾/病等相关,医生诊断(包含多个诊断结论),以及假设未来可能发生的疾病等,如:“如果不治疗的话,大概率会引起A疾病”,“A疾病”标注为阳性
(2)阴性(neg):未患有的疾病症状相关;
(3)其他(other):未知的标注其他,一般指用户没有回答、不知道或者回答不明确/模棱两可不好推断的情况。
(4)不标注(empty):无实际意义的不标注,一般是医生的解释说的是一般知识,和病人当前的状态条件独立不具有标注意义,及有些检查项带疾病名称的,识别的疾病(
乙肝
五项/
乙肝
抗体),药品名中出现的“疾病”不标注。
三、标注例子
例子1:
病人:
医生您好,从昨天晚上开始
肚子一直疼,
,吃了布洛芬有所缓解。---- “肚子一直疼”标记
阳性
医生:
肚子疼,
是
上腹部疼
么?---- “肚子疼”标记
阳性
,是基于上文推断;“上腹部疼”标记
阴性
,基于下文推断。
病人:
不是,主要是
下腹部疼
。---- “下腹部疼”标记
阳性
;
医生:
是
针扎样的疼
么?---- “针扎样的疼”标注
其他
;
病人:
不知道,描述不出来,
有点抽筋的那种疼
。 ---- “针扎样的疼”标注
其他
;
……
医生:
这种情况考虑为急性肠胃炎导致的,急性肠胃炎可能除了
腹疼
之外,可能还会引起
腹泻
等,需要即时补充水分。---- “腹疼”和“腹泻”均标注为
不标注
,是医生解释医学常识。
.
例子2:
医生:
有
尿急尿频
吗? ----“尿急”、“尿频”标注
阳性
患者:
有点。
例子3:
医生:
请问
白带有异味
吗?
外阴痒
吗?----“白带有异味”标注
阳性
、“外阴痒”标注
阴性
患者:
外阴在一个月之前有些发
痒
,但是现在不
痒
,白带闻起来有点腥臭味----第一处“痒”标注
阳性
, 第二处“痒”标注
阴性
例子4:
医生:
有
头晕
呕吐吗?----“头晕”标注
其他
患者:
不确定是不是
头晕
,感觉不
头晕
但好像又是
头晕
---- 三个“头晕”均标注
其他
,用户的回答模棱两可不好判断,标注“其他”
例子5:
医生:
腹泻
几次了?有
呕吐腹痛
吗?----“腹泻”标
阳性
,“呕吐”-
阳性
“腹痛”-
阳性
患者:
从昨天到今天三四次,也没敢吃东西,吃点就要去厕所,其他都还好,昨天吃了不新鲜的水果,
患者:
吃完过一会儿就
肚子痛
,没
吐
,晚上喝点粥不知道能不能好点---- “肚子痛”标
阳性
,“吐”标
阴性
例子6:
患者:
坐起来就不怎么
痛
,躺着就
痛
,站着不动也不怎么
痛
,走路慢点也还好,快点就
痛
----四个“痛”,分别标注
阴性
,
阳性
,
阴性
和
阳性
例子7:
患者:
我前天打篮球扭到了脚踝,现在脚踝处很
疼
,并且已经
肿
了,该怎么治疗
医生:
你这属于踝关节扭伤,现在需要消
肿
,止
痛
治疗; ----“肿”、“痛”均标注
阳性
例子8:
患者:
我害怕是
糖尿病
。----“糖尿病”标注
阴性
,
医生:
你这个不是
糖尿病
,这种情况考虑是
肠炎,肠胃炎
。可以服用一些治疗
肠炎
药物,如康恩贝
肠炎
宁胶囊;----“糖尿病”标记
阴性
,第一个“肠炎”,“肠胃炎”均标注
阳性
,第二、三个“肠炎”均标记为
不标注
数据说明
·标注样本举例:
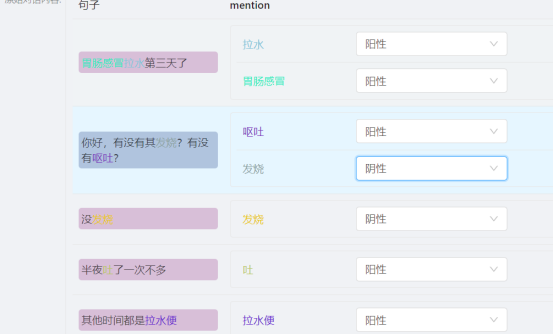
·导出数据示例(实际开放给选手的数据格式):
·数据格式说明:以json格式提供,包括如下字段:
- text:段落文本
- sender:患者或者医生
-
NER:实体的识别以及阴阳性的标签
- mention:短文中出现的和实体匹配的字段
- name:mention对应的标准名。 ·注:不是所有的mention都有对应的标准名
- range:mention在句子中的上下标
- type:实体类型,均统一成“clinical_findings”,不再区分症状或者疾病
- attr: 阴性/阳性/其他/不标注
本次评测共提供6000段对话语料作为训练集,测试分为两阶段,A、B榜单各提供2000段对话用来做测试数据,其中B榜提交时间会限制在48H内。
评价标准
测试数据只需要预测"attr"的部分,本评测采用Macro-F1作为评估指标。假设我们有n个类别,C1, … …, Ci, … …, Cn,计算公示如下:
准确率Pi = 正确预测为类别Ci的样本个数 / 预测为Ci类的样本个数。
召回率Ri = 正确预测为类别Ci的样本个数 / 真实的Ci类的样本个数。
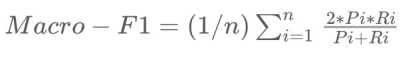
注:评价指标可能会追加个别类别(如“阴性”)的评分项,由任务组织方做出最终解释。
数据下载及任务提交
具体可以参照:
https://tianchi.aliyun.com/dataset/dataDetail?dataId=108859
评测比赛沟通群:请加钉钉群: 31756844
参赛规则
- 报名截止到测试数据集发布,在测试数据集发布之后,未报名的选手/队伍不能再报名或提交。
- 每名选手只能参加一支队伍,一旦发现某选手以注册多个账号的方式参加多支队伍,将取消所有相关队伍的参赛资格。
- 允许使用公开和选手个人/组织内部的代码、工具、数据,但需要保证参赛结果可以复现。
- 针对测试集,选手不允许执行任何人工标注。
- 参赛选手最终需要提交可运行的代码和方法描述文档,若在排行榜上的结果无法复现,将取消参赛资格。
- 欢迎国内外在校生及社会在职人士参加。比赛组织方成员不可参赛。
时间安排
- 报名时间:8月1日—10月29日
- 训练数据&初赛数据发布时间:9月12日—9月17日
- 初赛时间:9月1日-10月31日
- 复赛时间:11月3日-11月5日
- 代码审核时间:11月8日-11月14日
- 评测论文提交时间:11月15日
- CHIP会议日期(评测报告及颁奖):12月4日—6日
任务组织者
- 尹康平、董良,阿里巴巴夸克
- 陈漠沙、谭传奇,阿里云天池/阿里巴巴达摩院
- 汤步洲,哈尔滨工业大学(深圳),鹏城实验室
评测主席
- 雷健波,北京大学医学信息学中心(jianbolei@qq.com)
- 李作峰,飞利浦亚洲研究院(lizuofengcn@163.com)
- 汤步洲,哈尔滨工业大学(深圳)鹏城实验室(tangbuzhou@hit.edu.cn)