评测三:药品纸质文档识别与实体关系抽取任务
1. 任务背景
在医药流通行业,开展经营活动时积累了大量的纸质单据,如药品注册批件,药品GMP证书,药品生产许可证,药品说明书等。其中,药品说明书是载明药品的重要信息的法定文件,是选用药品的法定指南,具有较高的价值。
药品说明书的更新频率往往高于临床诊疗指南、医学教科书等常见语料来源,且提取难度较高,不同生产厂商的药品说明书虽然包含的内容相似,但版式上存在较多差异,且蕴含了结构化和非结构化的信息。从非结构化的文本中抽取药品与其他实体之间的关系,构建成医学知识图谱,可更好地服务于下游处方审核、辅助诊疗、患者健康宣教等任务。
2. 任务详情
按照药监局管理规定,药品说明书必须注明药品名称、成分、适应症、用法用量,不良反应等内容。本任务的目标既要求针对药品说明书的扫描件进行OCR识别,提取规定段落,形成结构化的数据,同时也需要从指定段落的非结构化文本中,将核心实体和关系挖掘出来。
| 实体名称 | 定义 | 例 |
|---|---|---|
| 药品 | 用于预防、治疗、诊断人的疾病,有目的地调节人的生理机能并规定有适应症或者功能主治、用法和用量的物质,包括中药、化学药和生物制品等 | 阿司匹林 |
| 疾病 | 在一定的病因作用下,机体内稳态调节紊乱而导致的生命活动障碍 | 新生儿黄疸 |
| 临床发现 | 包括症状、体征在内的临床观察见到的病人相关状态 | 发热 |
| 关系类型 | 关系子类型 | 定义 |
|---|---|---|
| 药品-疾病 | 适应症 | 指药品适用于某种疾病等情况。 |
| 药品-疾病 | 禁忌症 | 指药品不适宜或被禁止应用于某些疾病,使用后可引起严重不良后果。 |
| 药品-疾病 | 不良反应 | 指按正常使用药物进行预防、诊断或治疗时,引起与治疗目的无关的疾病。 |
| 药品-临床发现 | 适应症 | 指药品适用于某种症状或体征。 |
| 药品-临床发现 | 禁忌症 | 指药品不适宜或被禁止应用于某些症状或体征,使用后可引起严重不良后果。 |
| 药品-临床发现 | 不良反应 | 指按正常使用药物进行预防、诊断或治疗时,发生与治疗目的无关的有害反应。 |
| 药品-药品 | 药物相互作用 | 指同时或在一定时间内先后服用其他药物后会产生一些复合效应,可使药效加强或副作用减轻,也可使药效减弱或出现不应有的毒副作用。 |
| 药品-药品 | 相加作用 | 指与其他药物联合应用所产生的效应等于或接近分别应用所产生的效应之和。联用两种作用于同一部位或受体、且作用相同的药物,多呈相加作用。 |
| 药品-药品 | 协同作用 | 指与其他药物联合应用时,会达到彼此效应增强的效果。 |
| 药品-药品 | 拮抗作用 | 指与其他药物联合应用后,使得产生的效应减弱或消失,多数情况下不宜配对使用。 |
| 药品-药品 | 配伍禁忌 | 指药物在体外配伍直接发生物理性或化学性的相互作用而影响药物疗效或引起毒性反应的现象。 |
3. 数据说明
本次标注数据全部来源于药品说明书。
字段属性名未掺杂业务逻辑,采用说明书上原字段属性名。未在下列字段属性名中的字段不参与最终结果评估。
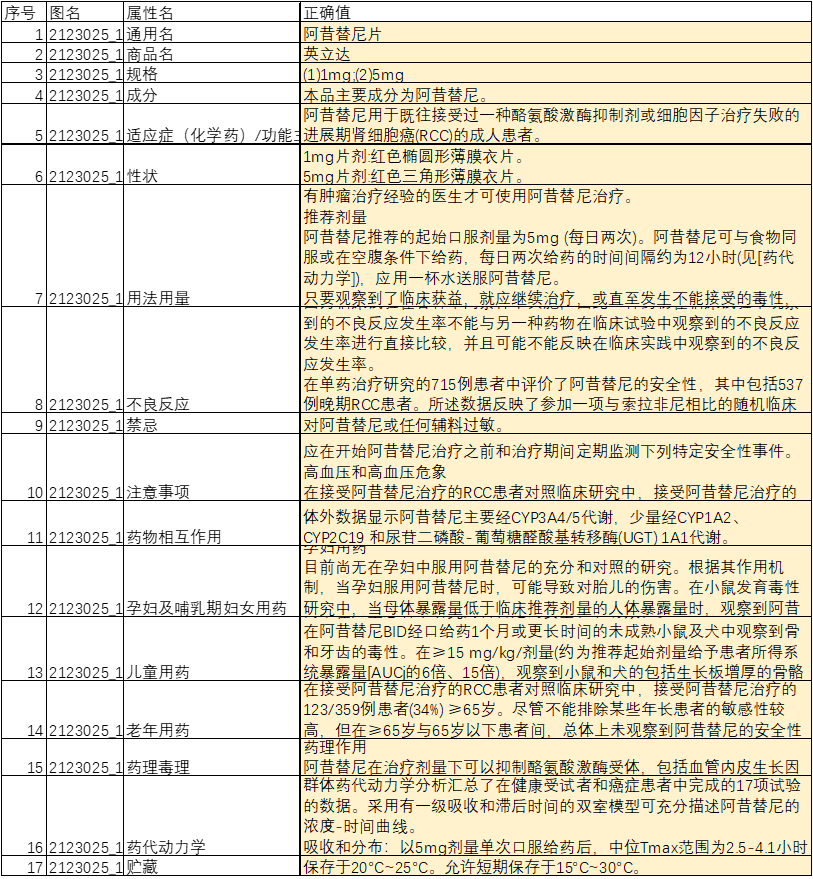
药品说明书字段(共17个):通用名,商品名,规格,成分,适应症(化学药)/功能主治(中成药),性状,用法用量,不良反应,禁忌,注意事项,药物相互作用,孕妇及哺乳期妇女用药,儿童用药,老年用药,药理毒理,药代动力学,贮藏
1.输入:药品所明书图片
2.输出:识别的字段以及符合规定类型的实体关系三元组,格式为JSON,包括以下内容:
“vertex” :源实体
“vertexName” :实体名称
“edgeType” :关系子类型
“target” :目标实体
“targetName” :目标实体名称
药品说明书图片示例:

药品说明书字段标注结果示例:
( “无”代表图片中未出现该字段)
药品说明书实体关系抽取结果示例:

1.源实体为当前说明书对应的药品。目标实体是从各个段落中提取到的药品,疾病,临床发现等。只需要抽取当前的药品与其他目标实体的关系,与当前药品不相关的实体关系(例如,在A说明书中,提到了B与C的关系)不考虑。
2.抽取疾病实体时,应包含疾病本身最直观的描述,其他定语、别名等不在抽取范围,例如“既往接受过索拉非尼治疗和/或含奥沙利铂系统化疗的晚期肝细胞癌(ACC)”,应当抽取的疾病实体为“肝细胞癌”。
3.针对多个实体连在一起的长mention,如果每个实体具备独立意义则分开标注,如“不良反应常有胃肠胀气和肠鸣音,偶有腹泻和腹胀,极少见有腹痛。”应标注临床发现“胃肠胀气”、“肠鸣音”、“腹泻”、“腹胀”、“腹痛”。
4.本任务只标注明确的正向关系,不考虑否定关系,如“A与B合用无显著影响”,不需要标注(A,B)。对于药物相互作用,若能明确是哪一种关系子类型的,还需要标注出具体的关系子类型,如“A与B会发生拮抗作用”,需要标注(A,B,药物相互作用)和(A,B,拮抗作用)
4. 评价标准
1.平均字符错误率(average-CER):所有字段的CER平均值,CER = 编辑距离/总字数。如果预测值和正确值皆为“无”则判定为“不计入计算”。
例:
| 属性名 | 正确值 | 预测值 | CER |
|---|---|---|---|
| 通用名 | 阿昔替尼片 | 阿昔替尼 | 20% |
| 商品名 | 英立达 | 英立达1 | 33.33% |
| 老年用药 | 无 | 无 | 不计入计算 |
2.三元组抽取的Macro-F1评分:假设我们有n个类别,C1, … …, Ci, … …, Cn,计算公示如下:
准确率Pi = 正确预测为类别Ci的样本个数 / 预测为Ci类的样本个数。
召回率Ri = 正确预测为类别Ci的样本个数 / 真实的Ci类的样本个数。
Macro-F1计算公示如下:
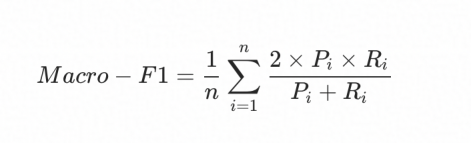
3.最终得分score = 0.3*(1 - average-CER)+0.7*Marco-F1
5. 评测数据
| 数据集 | 简介 |
|---|---|
| 识别训练集 | 真实数据图片及标注结果400张 |
| 识别评估A榜 | 真实数据图片及标注结果200张 |
| 识别评估B榜 | 真实数据图片及标注结果400张,提交时间会限制在48H内。 |